Table Of Content
Suppose engineers at a semiconductor manufacturing facility want to test whether different wafer implant material dosages have a significant effect on resistivity measurements after a diffusion process taking place in a furnace. They have four different dosages they want to try and enough experimental wafers from the same lot to run three wafers at each of the dosages. As an example, imagine you were running a study to test two different brands of soccer cleats to determine whether soccer players run faster in one type of cleats or the other. Further, imagine that some of the soccer players you are testing your cleats on only have grass fields available to them and others only have artificial grass or turf fields available to them. Now, say you have reason to believe that athletes tend to run 10% faster on turf fields than grass fields. Switch them around...now first fit treatments and then the blocks.
1 Data exploration
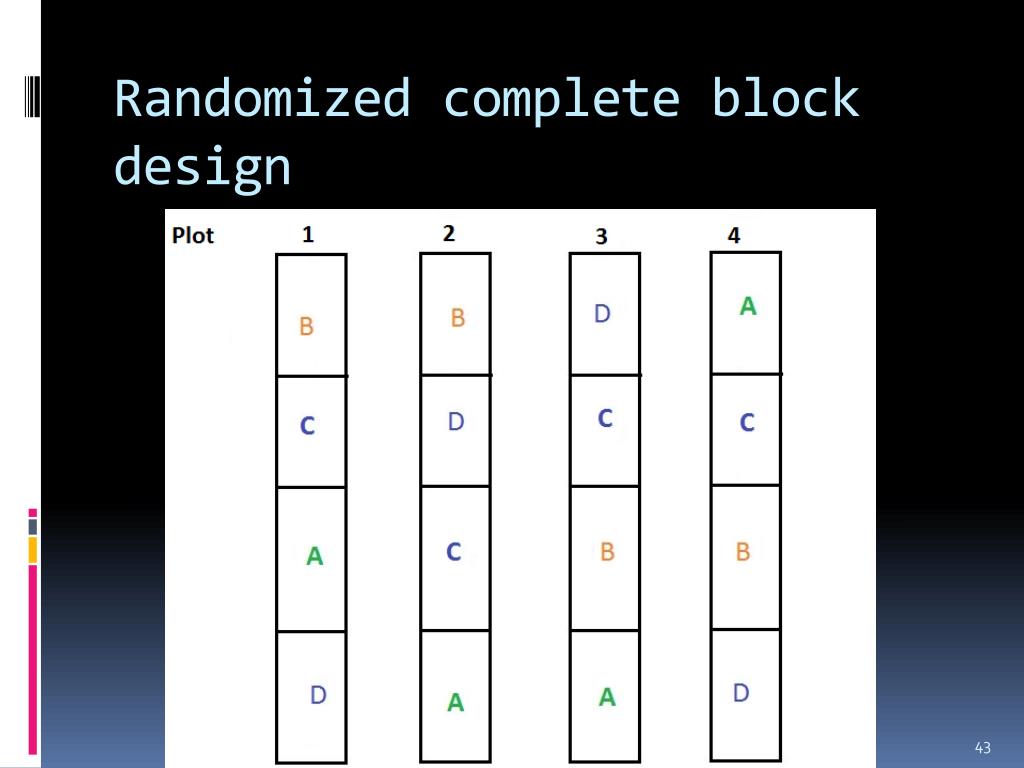
His work in developing analysis of variance (ANOVA) set the groundwork for grouping experimental units to control for extraneous variables. A randomized block design is an experimental design where the experimental units are in groups called blocks. The treatments are randomly allocated to the experimental units inside each block.
Random Allocation
Blocking first, then randomizing ensures that the treatment and control group are balanced with regard to the variables blocked on. If you think a variable could influence the response, you should block on that variable. BlockingWith small samples, it's possible to randomly divide the subjects and still get different groups. In order to address this, researchers “block” subjects into relatively homogeneous groups first and then randomly decide within each block who becomes a part of the control group and who becomes a part of the treatment group.
Randomized Block Design: An Introduction
For each experiment, identify (1) which experimental design was used; and (2) why the researcher might have used that design. Here are the main steps you need to take in order to implement blocking in your experimental design. Imagine an extreme scenario where all of the athletes that are running on turf fields get allocated into one group and all of the athletes that are running on grass fields are allocated into the other group. In this case it would be near impossible to separate the impact that the type of cleats has on the run times from the impact that the type of field has. Note that the least squares means for treatments when using PROC Mixed, correspond to the combined intra- and inter-block estimates of the treatment effects. Since the first three columns contain some pairs more than once, let's try columns 1, 2, and now we need a third...how about the fourth column.
Properties of sandcrete blocks stabilized with cashew apple ash as a partial replacement for cement Scientific Reports - Nature.com
Properties of sandcrete blocks stabilized with cashew apple ash as a partial replacement for cement Scientific Reports.
Posted: Thu, 21 Mar 2024 07:00:00 GMT [source]
Research plumbs the molecular building blocks for light-responsive materials - Argonne National Laboratory
Research plumbs the molecular building blocks for light-responsive materials.
Posted: Tue, 16 Mar 2021 07:00:00 GMT [source]
This is usually a constraint given from the experimental situation. And then, the researcher must decide how many blocks are needed to run and how many replicates that provides in order to achieve the precision or the power that you want for the test. Repeated Measures design is an experimental design where the same participants participate in each independent variable condition. This means that each experiment condition includes the same group of participants. By extension, note that the trials for any K-factor randomized block design are simply the cell indices of a k dimensional matrix. In our previous diet pills example, a blocking factor could be the sex of a patient.
What is Blocking?
For a complete block design, we would have each treatment occurring one time within each block, so all entries in this matrix would be 1's. For an incomplete block design, the incidence matrix would be 0's and 1's simply indicating whether or not that treatment occurs in that block. A special case is the so-calledLatin Square design where we have two blockfactors and one treatment factor having \(g\) levels each (yes, all of them!).Hence, this is a very restrictive assumption. In a Latin Square design, eachtreatment (Latin letters) appears exactly once in each row and once ineach column.
Each oven run would have four loaves, but not necessarily two of each dough type. (The exact proportion would be chosen randomly.) You would have 5 oven runs for each temperature; this could help you to account for variability among same-temperature oven runs. At a high level, blocking is used when you are designing a randomized experiment to determine how one or more treatments affect a given outcome.
Want to Pass Your Six Sigma Exam the First Time through?
We could put individuals into one of two blocks (male or female). And within each of the two blocks, we can randomly assign the patients to either the diet pill (treatment) or placebo pill (control). By blocking on sex, this source of variability is controlled, therefore, leading to greater interpretation of how the diet pills affect weight loss. Experimental design refers to how participants are allocated to different groups in an experiment. Types of design include repeated measures, independent groups, and matched pairs designs. Note, that the power is indeed much larger for the randomized complete block design.
For example, consider if the drug was a diet pill and the researchers wanted to test the effect of the diet pills on weight loss. The explanatory variable is the diet pill and the response variable is the amount of weight loss. Although the sex of the patient is not the main focus of the experiment—the effect of the drug is—it is possible that the sex of the individual will affect the amount of weight lost.
If you have doubts on that your data violates the assumptions you can always simulate data from a model with similar effects as yours but where are distributional assumptions hold and compare the residual plots. In the most basic form, we assume that we do not have replicateswithin a block. This means that we only observe every treatment once in eachblock. The nuisance factor they are concerned with is "furnace run" since it is known that each furnace run differs from the last and impacts many process parameters.
The single design we looked at so far is the completely randomized design (CRD) where we only have a single factor. In the CRD setting we simply randomly assign the treatments to the available experimental units in our experiment. If we choose one of the RCB Design Structures, Temperature effects are completely randomized at the Run level. Recipe is nested within temperature and has a different error structure than temperature, because each dough appears within each run.
It is good practice to write the block factor first; incase of unbalanced data, we would get the effect of variety adjusted for blockin the sequential type I output of summary, see Section 4.2.5and also Chapter 8. In Design of Experiments, blocking involves recognizing uncontrolled factors in an experiment–for example, gender and age in a medical study–and ensuring as wide a spread as possible across these nuisance factors. Let’s take participant gender in a simple 3-factor experiment as an example. The final step in the blocking process is allocating your observations into different treatment groups. All you have to do is go through your blocks one by one and randomly assign observations from each block to treatment groups in a way such that each treatment group gets a similar number of observations from each block. The first step of implementing blocking is deciding what variables you need to balance across your treatment groups.
For example, if the study contains the place as a blocking factor, the results could be generalized for the places. A fertilizer producer can only claim that it is effective regardless of the climate conditions when it is tested in various climate conditions. In this case, you would run the oven 40 times, which might make data collection faster.
Therefore, it would be very useful to block on gender in order to remove its effect as an alternative explanation of the outcome. And because physical capability differs substantially between males and females, the authors decided to block on gender. So in both experiments we need to do six mass spectrometry runs. We can create a (random) Latin Square design in R for example with thefunction design.lsd of the package agricolae (de Mendiburu 2020). Connect and share knowledge within a single location that is structured and easy to search.
After that, we discuss when you should use blocking in your experimental design. Finally, we walk through the steps that you need to take in order to implement blocking in your own experimental design. When we have missing data, it affects the average of the remaining treatments in a row, i.e., when complete data does not exist for each row - this affects the means. When we have complete data the block effect and the column effects both drop out of the analysis since they are orthogonal. With missing data or IBDs that are not orthogonal, even BIBD where orthogonality does not exist, the analysis requires us to use GLM which codes the data like we did previously.